Claude 3 Opus vs GPT-4 当下最强大语言模型的对比
起源自海外媒体的测评(via Medium),性能测评方面概述是这样的,但我进一步做个解读
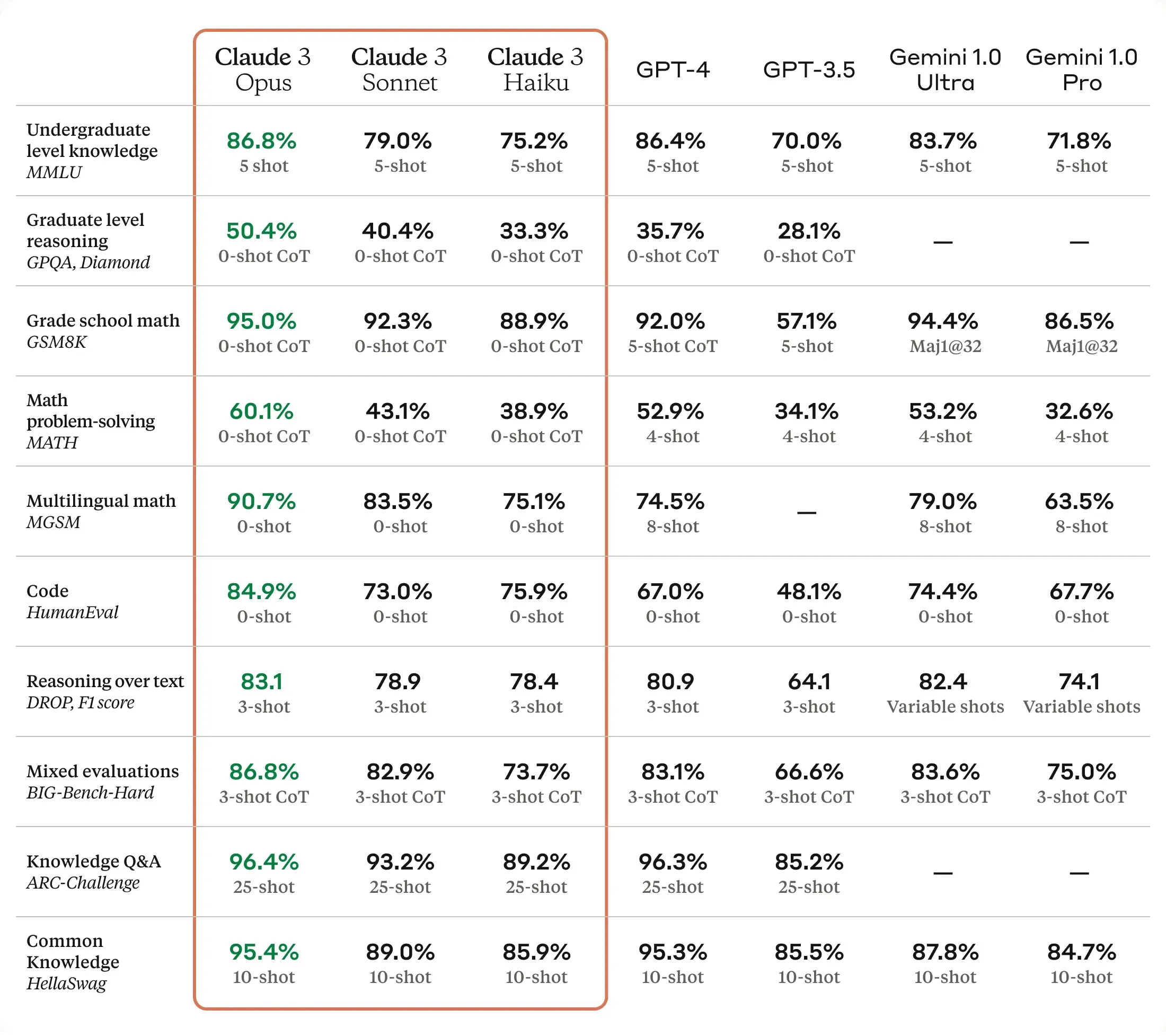
「使用 Claude 3 (Opus) 进行的基准测试显示,在本科水平的知识(86,8% 对 86,4%)、研究生水平推理(50,4% 对 35,7%)、小学数学(95% 对 92%)、数学问题解决(60,1% 对 52,9%)、多语言数学(90,7% 对 74,5%)、代码(84,9% 对 67%)、文本推理(83,1% 对 80,9%)等方面,Claude 3 Opus 比 GPT4 的准确性更高。」
具体图表如下图:
Claude 3 VS GPT-4
Claude 3 与 GPT-4 对比解读
详细解读如下:
- 本科知识方面,Claude 3 Opus、GPT-4和Gemini 1.0 Ultra表现最为出色,5-shot情况下分数均在83%以上。
- 研究生水平推理能力上,Claude 3 Opus显著强于其他模型,0-shot CoT达到50.4%,而Gemini 1.0模型暂未提供此项评估结果。
- 初中数学题解题能力方面,Claude 3 Opus再次表现优异,0-shot CoT达95%,远超GPT-4的5-shot 92%成绩。
- 数学词问题解决上,GPT-4在4-shot情况下略强于Gemini Ultra,但Gemini Pro的表现相对较差。
- 多语种数学问题解决能力,Claude 3 Opus以90.7%的0-shot成绩领先,GPT-4的8-shot评估也仅为74.5%。
- 编码能力上,Gemini Ultra的74.4%成绩最高,Claude模型也有不错的表现。
- 文本推理方面,Claude 3系列和Gemini Ultra的F1分数在78-83之间,GPT-4以80.9分数稍逊一筹。
- BIG-Bench-Hard综合评估中,Gemini 1.0 Ultra的3-shot CoT成绩83.6%最高,Claude 3 Opus次之。
- 知识问答任务上,Claude模型的25-shot成绩在89-96%之间,表现出色,与GPT-4相当。
- 常识知识的测评中,Claude 3 Opus以95.4%的10-shot分数领先。
总的来看啊。Anthropic的Claude 3系列模型在很多评估维度上表现出众,尤其是数学、推理和知识问答等领域,不过GPT-4和Gemini模型在某些特定任务上也有不俗的成绩。不同模型在不同领域具有自身的优势,未来或可集成互补以发挥最佳效能。
挑重点来说,面向科研用户、编码需求的客户,真的很有必要试试 Claude 3 的 Opus 版本。
附大语言模型的评估维度
上述图表对比了几个大型语言模型在不同任务和评估维度上的性能表现,包括Anthropic的Claude 3系列变体、OpenAI的GPT-4和GPT-3.5,以及Google的Gemini 1.0等模型。评估维度包括:
- 本科知识(Undergraduate level knowledge)
- 使用MMLU数据集,评估模型在常识性和通用知识方面的表现,结果显示为5-shot(给出5个示例)的情况。
- 研究生层次推理(Graduate level reasoning)
- 使用GPQA Diamond数据集,0-shot CoT评估模型在高级推理和复杂问题解决方面的能力。
- 初中数学(Grade school math)
- 使用GSM8K数据集,0-shotCoT和5-shot等情况评估模型解决中学数学题的水平。
- 数学问题解决(Math problem-solving)
- MATH数据集,4-shot情况下评估模型解决数学词问题的能力。
- 多语言数学(Multilingual math)
- MGSM数据集,0-shot和8-shot情况下考察模型解决多语种数学问题的表现。
- 编码能力(Code)
- HumanEval数据集,0-shot下评估模型编写代码的水平。
- 文本推理(Reasoning over text)
- DROP数据集,3-shot和variable shots情况评估基于文本的推理和问答能力。
- 综合评估(Mixed evaluations)
- BIG-Bench-Hard数据集,3-shot CoT整体测试模型的多项能力。
- 知识问答(Knowledge Q&A)
- ARC-Challenge数据集,25-shot情况下考察模型的知识问答水平。
- 常识知识(Common Knowledge)
- HellaSwag数据集,10-shot条件下评估模型对日常常识的掌握程度。
可以说,这些维度全面评估了大型语言模型在知识理解、推理能力、数学和编码、多语种处理、综合问答等多个方面的表现,涵盖了自然语言处理的多个核心能力。提到的这些专业名词的具体释义,你可以问问ChatGPT和Claude~
Claude AI 成品号购买
更新:本店已上架 Claude 3 成品号,买来即用,体验最佳最方便↓
Claude 3 成品普号 Sonnet 回复质量高,能识别图片- 克劳德AI – 49元 立即购买



